BYOD (Bring Your Own Device) is now a paradigm that is tightly integrated into IT spectrum. IMO, Android One helps simplify the life of IT staff while handling user owned devices that operate on data that is owned by the organizations.
The IT staff’s ownership over the client devices/end points is reducing very fast in recent years. This is due to the use cases that focus on end users, service providers, partners and internal employees that are continuously contributing to the data of an organization. Despite reducing level of ownership of these devices, the IT staff continue to have a responsibility to prove that they have adequate controls over these devices and their data.
For example, signatures of customers and delivery details on delivery personnel’s client devices should be ascertained with to all the integrity and confidentiality controls by IT staff of any shopping website and its delivery partners. There were times when the client devices are custom made solutions for the delivery companies, but smart phones are rapidly replacing these legacy client devices. More often than not, these smart phones are owned and updated by individuals rather than organizations. Hence these BYOD devices pose a challenge to the IT staff and increase threat to the data confidentiality and integrity.
The major challenge for IT staff is to ensure that all the nomadic client devices are running approved, stable and latest stack. In olden days (say about 10 years ago), the client devices are mostly laptops that need to be patched and upgraded regularly, along with appropriate user access controls on these devices. With the proliferation of smart phones as client devices, the challenge goes multi-fold. Wearing an IT Professional’s hat, I do see every smart phone like this:
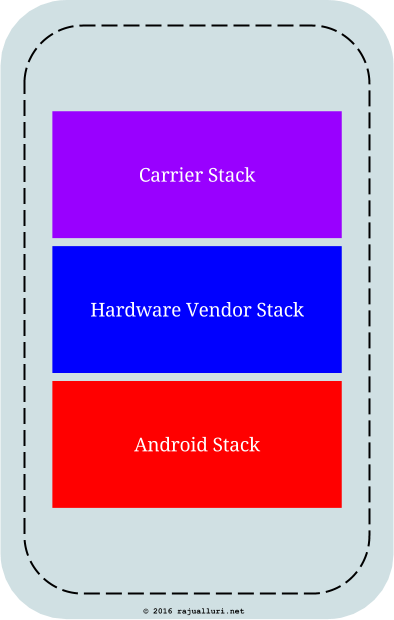
The moment I think about manageability of that smart phone (not ownership of the smart phone, which is never going to happen), I see the smart phone as
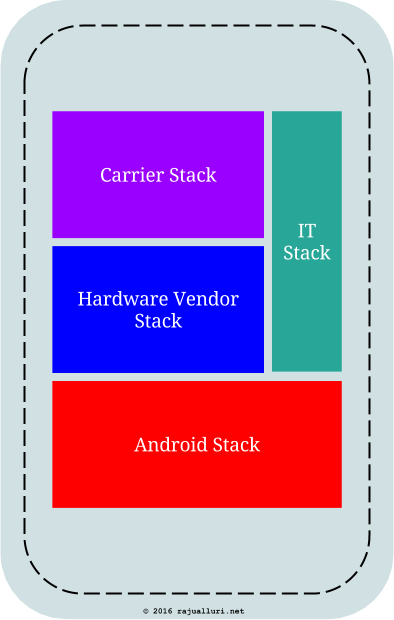
The IT stack in the above picture is a combination of various off-the-shelf and home grown applications, together with well tested configurations of these applications. More often than not, the IT stack applications and configurations heavily depend on the underlying Android Stack. That means it pays to support these applications and configurations on a limited set of latest versions of Android.
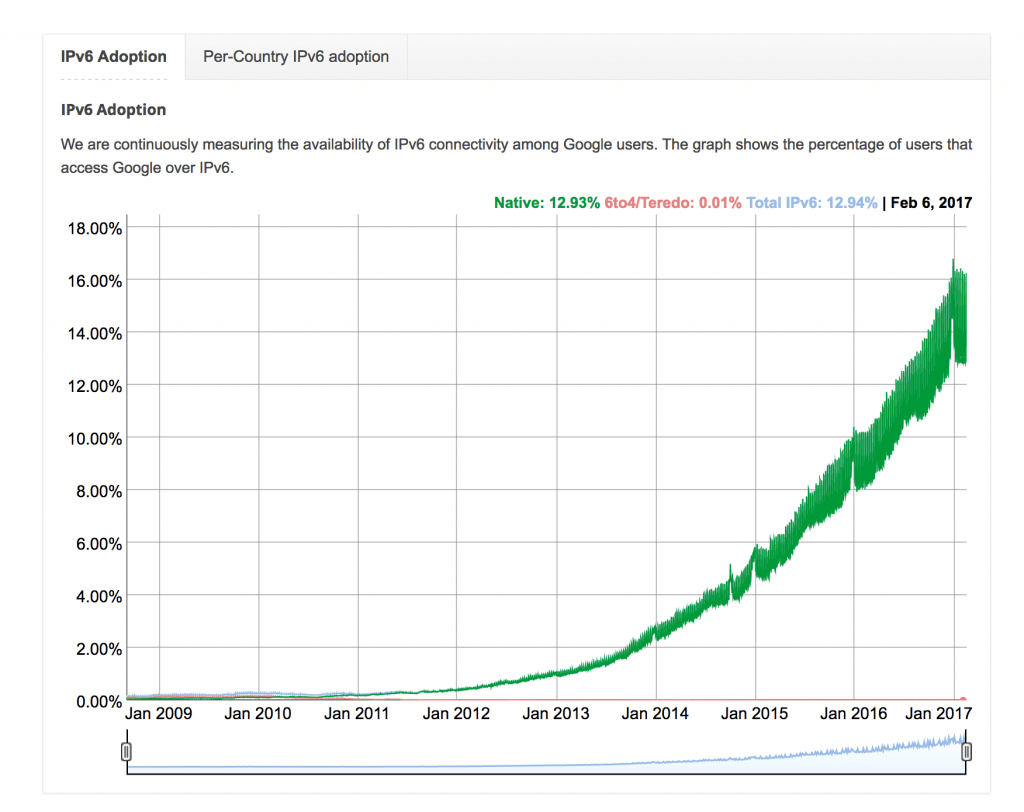
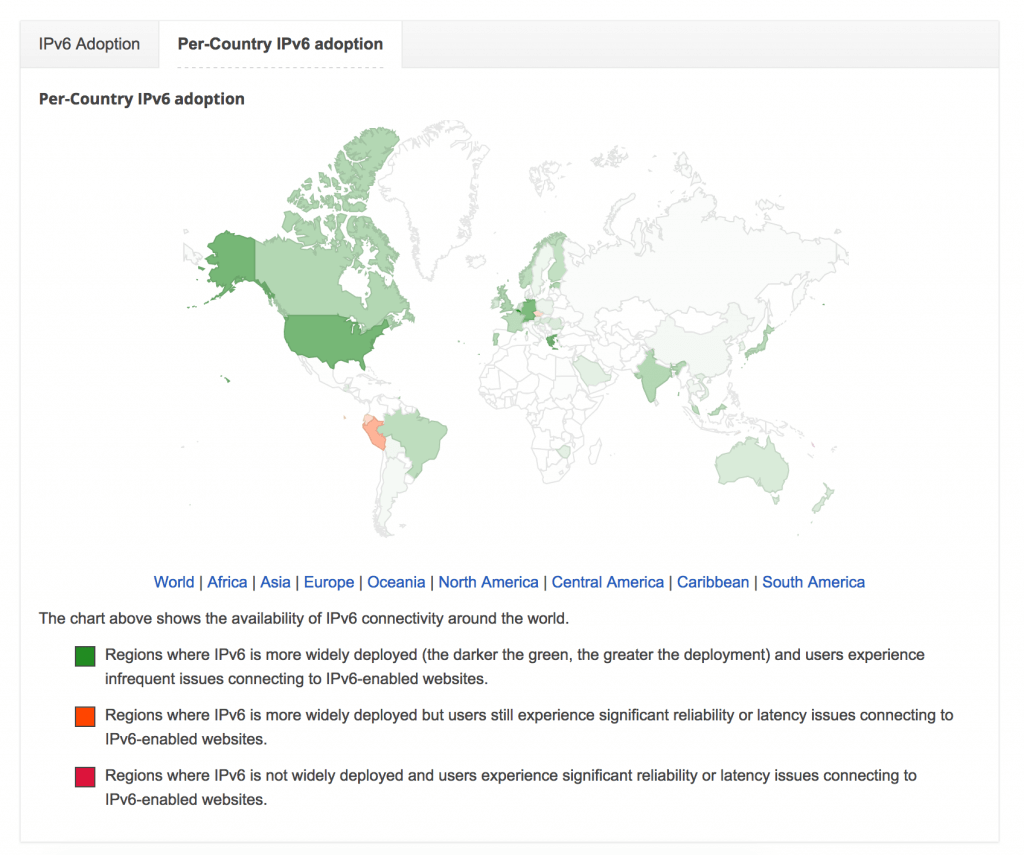
When it comes to the upgrades (read patching) of the Android stack, both the carrier and vendor have long release cycles in place for stack upgrades on target devices. As a result, most smart phones that are more than a year old end up running Android versions that are old and probably not patched fast enough. This is true with any mobile OS though, not just with Android.
Supporting the IT Stack in the above picture is a nightmare for IT staff if they are to support this on multiple and older versions of mobile operating systems. Due to this, the IT staff may want the mobile phones to run with the latest OS. But the large release cycles of phone vendors and carriers often become a hurdle to accomplish this.
Android One (https://www.android.com/one/) is the best solution out of that version control mess. I have been using a cost effective and reasonably powered Android One phone since 2014. Over the last year and half, this phone has become my device of choice for use cases that strictly require latest versions of Android Platform and its eco system. The use cases include IT tools like VPN connectivity apps, single sign-on solutions, device control/erase solutions, messaging solutions and sharing solutions. This $100 unlocked dual SIM phone is a very reasonable investment for accomplishing adherence to stringent IT policies.
Android One is supported by phones that are very high end (e.g. the Nexus series sold directly by Google) all the way to cost effective phones in emerging economies. In almost all cases, the phones come with unlocked versions, leaving a wider choice of carriers to customers.
Updates to my Android One smartphone have been regular and painless in the last year and half. The ability to grab the latest update of Android within a few hours makes Android One my preferred choice.
In any BYOD centered IT infrastructure, Android One is the best way to go for IT staff to enforce tighter IT policies on smart phones while ensuring that the user devices are running with latest version of the mobile stack. That in turn ensures that the IT stack on the smartphone is current and easy to manage.